
Introduction to Apache Spark with Scala
Published:

This article is a follow-up note for the March edition of Scala-Lagos meet-up where we discussed Apache Spark, it’s capability and use-cases as well as a brief example in which the Scala API was used for sample data processing on Tweets. It is aimed at giving a good introduction into the strength of Apache Spark and the underlying theories behind these strengths.
Spark - An all encompassing Data processing Platform

“If there’s one takeaway it’s just that it’s okay to do small wins. Small wins are good, they will compound. If you’re doing it right, the end result will be massive.” - Andy Johns
Apache Spark is a highly developed engine for data processing on large scale over thousands of compute engines in parallel. This allows maximizing processor capability over these compute engines. Spark has the capability to handle multiple data processing tasks including complex data analytics, streaming analytics, graph analytics as well as scalable machine learning on huge amount of data in the order of Terabytes, Zettabytes and much more.
Apache Spark owns its win to the fundamental idea behind its development - which is to beat the limitations with MapReduce, a key component of Hadoop, thus far its processing power and analytics capability is several magnitudes, 100×, better than MapReduce and with the advantage of an In-memory processing capability in that, it is able to save its data in compute engine’s memory (RAM) and also perform data processing over this data stored in memory, thus eliminating the need for a continuous Input/Output(I/O) of writing/reading data from disk.
To effectively do this, Spark relies on the use of a specialized data model known as Resilient Distributed Dataset (RDD), that can be effectively stored in-memory and allows for various types of operations. RDDs are immutable i.e read-only format of data items that are stored in-memory as well as effectively distributed across clusters of machines, one can think of RDD as a data abstraction over raw data format e.g String, Int, that allows Spark does its work very well.
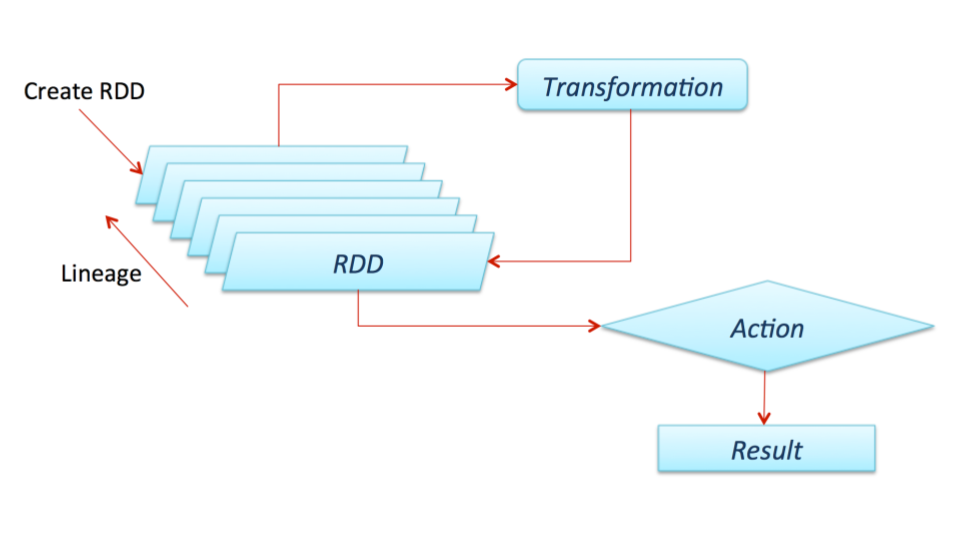
Beyond RDD, Spark also makes use of Direct Acyclic Graph (DAG) to track computations on RDDs, this approach optimizes data processing by leveraging the job flows to properly assign performance optimization, this also has an added advantage that helps Spark manage errors when there is job or operation failures through an effective rollback mechanism. Therefore, in cases of errors, Spark doesn’t need to start computation from the beginning, it can easily make use of the RDD computed before the error and pass it through the fixed operation. This is why Spark is designated as a fault-tolerant processing engine.
Spark also leverage a cluster manager to properly run its job across a cluster of machines, the cluster manager helps with resource allocation and scheduling of job in a master - worker fashion. A Master distributes jobs and allocate necessary resources to the workers in the cluster, and coordinate the worker’s activity such that in cases of a worker being unavailable, the job is reassigned to another worker.
With the idea of in-memory processing using RDD abstraction, DAG computation paradigm, resource allocation and scheduling by the cluster manager, Spark has gone to be an ever progressing engine in the world of fast big data processing.
Spark Data Processing Capabilities.
Structured SQL for Complex Analytics with basic SQL
A well-known capability of Apache Spark is how it allows data scientist to easily perform analysis in an SQL-like format over very large amount of data. Leveraging spark-core internals and abstraction over the underlying RDD, Spark provides what is known as DataFrames, an abstraction that integrates relational processing with Spark’s functional programming API. This is done, by adding structural information to the data to give semi-structure or full structure to the data using schema with column names and with this, a dataset can be directly queried using the column names opening another level to data processing. Starting at version 1.6 of Spark, there is the Dataset API that comes with the Structured SQL API, it provides a high-level SQL-like capability to somewhat low-level RDD of Spark-core. In literal terms, Dataset API is an abstraction that gives an SQL feel and execution optimization to spark RDD by using the optimized SQL execution engine without also losing the functional operations that come with RDD. Both the Dataset API and Dataframe API forms the Structured SQL API.
Spark Streaming for real-time analytics
Spark also provides an extension to easily manipulate streaming data, by providing an abstraction over the underlying RDD in the form of Discretized Stream. Using the underlying RDD Spark core has two main advantages; it allows other core capabilities of Spark to be leveraged on Streaming Data as well as avail the data core operations that can be performed on RDDs. Discretized Stream of data means RDD data obtained in small real-time batches.
MLLib/ML Machine learning for predictive modelling
Spark also provides machine learning capability by providing machine learning algorithms, data featurization algorithms and pipelining capabilities optimized to be implemented to scale over large amount of data. Spark Machine learning library’s goal is summarized thus:
to make practical machine learning scalable and easy.
GraphX Graph Processing Engine.
The fourth data processing capability is inherent in its capability to perform analysis on Graph data e.g in social network analysis. Spark’s GraphX API is a collection of ETL processing operations and graph algorithms that are optimized for large scale implementations on data.
Initializing Spark.
There are several approaches to initialize a Spark application depending on the use case, the application may be one that leverages RDD, Spark Streaming, Structured SQL with Dataset or DataFrame. Therefore, it is important to understand how to initialize these different Spark instances.
1. RDD with Spark Context:
Operations with spark-core are initiated by creating a spark context, the context is created with a number of configurations such as the master location, application names, memory size of executors to mention a few.
Here are two ways to initiate a spark context as well as how to make an RDD with the created spark context.
2. DataFrame/Dataset with Spark Session:
As observed above, an entry point to Spark could be by using the Spark Context, however, Spark allows direct interaction with the Structured SQL API with Spark Session. It also involves specifying the configuration for the Spark app.
Here is the approach to initiate a Spark Session and create a Dataset and DataFrame with the Session.
3. DStream with Spark Streaming:
The other entry point to Spark is using the Streaming Context when interacting with real-time data. An instance of Streaming Context can either be created from a Spark Configuration or a Spark Context. This is shown below
Operations on RDD, Datasets and DataFrame
Having seen a good glimpse into the capability of Spark, it’s important to show some operations that can be applied over the various spark’s abstraction.
1. RDD
RDD, which is Spark’s main abstraction and more at the center of the spark-core has two basic operations.
Transformations - Transformations operations are applied on existing RDD to create new and changed RDDs. Example of such operations include
map,filterandflatMapto mention a few. A full list of transformation operations in Spark can be found here. Once spark Context has been used to create an RDD, these operations can be applied on the RDD as seen in the code sample below. It is important to note that the operations are lazily evaluated in that they are not directly computed until an Action operation is applied.Actions - Actions operations triggers an actual computation in Spark, it drives computation to return a value to the driver program. The idea of action operations is to return all computations from the cluster to the driver to produce a single result in actual Data types away from the RDD abstraction of spark. Care must be taken when initiating action operations because it’s important that the driver has enough memory to manage such data. Example of action operations includes
reduce,collectandtaketo mention a few. The full list can be found here.
2. DataSet/DataFrame
As mentioned earlier, Dataset is the RDD-like optimized abstraction for Structured SQL that allows both relational operations like in SQL and functional operations like map, filter and many other similar operations that are possible with RDD. It is important to emphasize that not all DataFrame SQL-like capability are fully available with Dataset however there are many column-based functions that are still very much available with Dataset. Also, there is an added advantage of encoding Datasets in domain-specific objects i.e mapping a dataset to a type T this helps extends the functional capabilities that are possible with Spark Dataset adding also the ability to perform powerful lambda operations.
Spark DataFrame can further be viewed as Dataset organized in named columns and presents as an equivalent relational table that you can use SQL-like query or even HQL. Thus, on Spark DataFrame performing any SQL-like operations such as SELECT COLUMN-NAME, GROUPBY and COUNT to mention a few becomes relatively easy. Another interesting thing about Spark DataFrame is that these operations can be done programatically using any of the available spark APIs - Java, Scala, Python or R as well as converting the DataFrame to a temporary SQL table in which pure SQL queries can be performed on.
Conclusion.
To conclude this introduction to Spark, a sample scala application - wordcount over tweets is provided, it is developed in the scala API. The application can be run in your favorite IDE such as InteliJ or a Notebook like in Databricks or Apache Zeppelin. In this article, some of the major points covered are:
- Description of Spark as a next generation data processing engine
- The undelying technology that gives spark its capability
- Data Processing APIs that exists in Spark
- A knwoledge of how to work with the Data Processing APIs
- A simple example to have a taste of spark processing power.
Leave a Comment