
Machine Learning Operations At Scale (part 2)
Published:
Setting up an Orchestration Engine for Machine learning operations with Kubernetes and Kubeflow.
Hello!
This is the Part 2 of the Machine learning operations at scale article, the part 1 is basically an introduction and can be found here.
In this article, I will highlight setting up the orchestration environment which I believe is one of the most important environment to actually do MLOPs.
Importance of Orchestration
Orchestration allows you to build what is called a Pipeline for machine learning models. This is a fancy word for chaining together the various stages of machine learning steps first part which is the data science stage comprising of data extraction, feature engineering, model building, hyperparameter tuning and a second part which is the actual production consideration which includes, data versioning, monitoring, model deployment and model versioning.
There are several tools that people use for orchestration. Some allows you to do a more robust orchestration example of which is Kubeflow since it also relies on the capability of Kubernetes hence you also have the orchestration capability of Kubernetes for free. Others are a little easy to get by, at least they try to keep things simple compared to managing Kubernetes cluster. I am thinking of Airflow, Luigi and Mlflow in this category.
Hello Kubeflow!
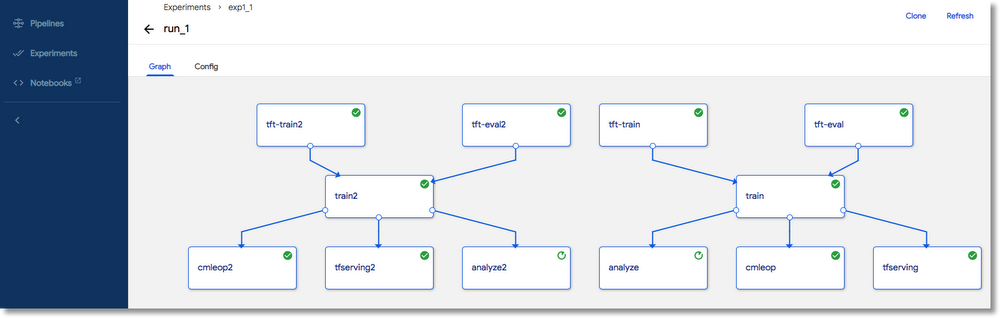
With Airflow though, you can easily create an end to end pipeline of whatever project you want that may be ran even via Docker (as this is not always necessary but useful in case you need it too) and once you deploy your pipeline, you can also trigger it with maximum flexibility depending on your engineering prowess. With Airflow orchestration though, you will need some important software development skills - who doesn’t need this anyways.
In general, orchestration mechanism is how you create a pipeline and chain your machine learning process for each single model that you would want to deploy and maintain in production.
Setting up local Kubeflow.
For setting up our environment, the first thing we need to get out of the way is the bone behind kubeflow which is Kubernetes. What is Kubernetes? Kubernetes is an engine for managing container environments to help achieve provisioning app deployments at scale using something as basic as a yaml file configuration.
Side Note: The fact that Kubernetes is provisioned with yaml file doesn’t make it easy to manage. Management of kubernetes can be tedius and that leaves us to using it only when you are convinced it is the way to go.
If you are using Docker-desktop on Windows or MacOs, that is a very good place to start as you can easily initiate a single node kubernetes cluster with your docker desktop. The process is actually quite simple. This set up is officially documented on docker.
For linux users, an alternative is to use either one of the following tools:
- Kind
- Minikube
- k3s
Setup for minikube is also quite straight forward.
curl -LO https://storage.googleapis.com/minikube/releases/latest/minikube-linux-amd64
sudo install minikube-linux-amd64 /usr/local/bin/minikube
And we can create a cluster with
minikube start
For further details on installing a local kubernetes cluster with minikube in case you encounter an issue, check here.
Similar to minikube, the setup for kind is also very straight forward:
curl -Lo ./kind https://kind.sigs.k8s.io/dl/v0.11.1/kind-linux-amd64
chmod +x ./kind
mv ./kind /some-dir-in-your-PATH/kind
And you can start a new cluster with kind create cluster --name your-cluster-name
Refer to the kind documentation for further issue resolution in case of any issues.
The above setups needs docker as its backend to help create the kubernetes deployment and they are a little resource intensive and takes time when creating the cluster hence you have to at least be good with RAM and Storage space.
Wow, that was a lot to take in, although k3s boast a somewhat light weight kubernetes deployment however we will not delve into that.
Once done with the kubernetes deployment, the next thing is to deploy kubeflow on our kubernetes cluster.
Important concept to know in the world of kubernetes is the namespace concept the kind of application which could be Deployment, Service and some other others. This are important when creating the configuration for your application. Interestingly some tools already created this configuration and that leaves us with just applying them to our kubernetes cluster.
Setting up Kubeflow for kubernetes.
You will need to download the the manifests for kubeflow. A best approach was to clone the kubeflow pipeline repository, this will allow you have access to the needed manifest to run the below commands
kubectl apply -k "kubeflow/pipelines/manifests/kustomize/cluster-scoped-resources
kubectl wait --for condition=established --timeout=60s crd/applications.app.k8s.io
kubectl apply -k "kubeflow/pipelines/manifests/kustomize/env/platform-agnostic-pns
The above code often takes a little time, but if all goes well which in many case will if you have adequate resource, you should have a kubeflow environment running.
Remember, the essence of this process is generally to have our orchestration engine that will help manage several machine learning model pipelines.
You can verify that the kubeflow environment is working perfectly by port-forwarding the running kubeflow on kubernetes to the local system:
kubectl port-forward -n kubeflow svc/ml-pipeline-ui 8080:80
Once this is done, we can play around creating simple pipeline configurations from python or uploading a yaml file to our kubeflow UI.
"""
End to end simple pipeline
"""
import kfp
import logging
from kfp import components
def merge_csv(file_path: components.InputPath('Tarball'),
output_csv: components.OutputPath('CSV')):
import glob
import pandas as pd
import tarfile
tarfile.open(name=file_path, mode="r|gz").extractall('data')
df = pd.concat(
[pd.read_csv(csv_file, header=None)
for csv_file in glob.glob('data/*.csv')])
df.to_csv(output_csv, index=False, header=False)
# Web downloader component - Can be reused anywhere
web_downloader_op = kfp.components.load_component_from_url(
url= 'https://raw.githubusercontent.com/kubeflow/pipelines/master/components/web/Download/component.yaml'
)
create_step_merge_csv = kfp.components.create_component_from_func(
func=merge_csv,
output_component_file='component.yaml',
base_image='python:3.8',
packages_to_install=['pandas==1.1.4']
)
def example_pipeline(url):
web_downloader_task = web_downloader_op(url=url)
create_step_merge_csv(file=web_downloader_task.outputs['data'])
if __name__ == "__main__":
client = kfp.Client(
host="http://localhost:8080"
)
client.create_run_from_pipeline_func(
pipeline_func=example_pipeline,
arguments={
'url' : 'https://storage.googleapis.com/ml-pipeline-playground/iris-csv-files.tar.gz'
}
)
logging.info("Done creating pipeline...")
# You can auto create a yaml configuration of your pipeline with this.
kfp.compiler.Compiler().compile(
pipeline_func=example_pipeline,
package_path='pipeline_starter/pipeline.yaml')
And the final pipeline yaml will eventually look like this
apiVersion: argoproj.io/v1alpha1
kind: Workflow
metadata:
generateName: example-pipeline-
annotations: {pipelines.kubeflow.org/kfp_sdk_version: 1.6.4, pipelines.kubeflow.org/pipeline_compilation_time: '2021-07-04T15:25:19.247514',
pipelines.kubeflow.org/pipeline_spec: '{"inputs": [{"name": "url"}], "name": "Example
pipeline"}'}
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.6.4}
spec:
entrypoint: example-pipeline
templates:
- name: download-data
container:
args: []
command:
- sh
- -exc
- |
url="$0"
output_path="$1"
curl_options="$2"
mkdir -p "$(dirname "$output_path")"
curl --get "$url" --output "$output_path" $curl_options
- ''
- /tmp/outputs/Data/data
- --location
image: byrnedo/alpine-curl@sha256:548379d0a4a0c08b9e55d9d87a592b7d35d9ab3037f4936f5ccd09d0b625a342
inputs:
parameters:
- {name: url}
outputs:
artifacts:
- {name: download-data-Data, path: /tmp/outputs/Data/data}
metadata:
annotations: {author: Alexey Volkov <alexey.volkov@ark-kun.com>, pipelines.kubeflow.org/component_spec: '{"implementation":
{"container": {"command": ["sh", "-exc", "url=\"$0\"\noutput_path=\"$1\"\ncurl_options=\"$2\"\n\nmkdir
-p \"$(dirname \"$output_path\")\"\ncurl --get \"$url\" --output \"$output_path\"
$curl_options\n", {"inputValue": "Url"}, {"outputPath": "Data"}, {"inputValue":
"curl options"}], "image": "byrnedo/alpine-curl@sha256:548379d0a4a0c08b9e55d9d87a592b7d35d9ab3037f4936f5ccd09d0b625a342"}},
"inputs": [{"name": "Url", "type": "URI"}, {"default": "--location", "description":
"Additional options given to the curl bprogram. See https://curl.haxx.se/docs/manpage.html",
"name": "curl options", "type": "string"}], "metadata": {"annotations":
{"author": "Alexey Volkov <alexey.volkov@ark-kun.com>"}}, "name": "Download
data", "outputs": [{"name": "Data"}]}', pipelines.kubeflow.org/component_ref: '{"digest":
"25738efc20b7c1bfeb792f872d2ccf88097f15f479a36674d712da20290bf79a", "url":
"https://raw.githubusercontent.com/kubeflow/pipelines/master/components/web/Download/component.yaml"}',
pipelines.kubeflow.org/arguments.parameters: '{"Url": "",
"curl options": "--location"}'}
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.6.4, pipelines.kubeflow.org/pipeline-sdk-type: kfp}
- name: example-pipeline
inputs:
parameters:
- {name: url}
dag:
tasks:
- name: download-data
template: download-data
arguments:
parameters:
- {name: url, value: ''}
- name: merge-csv
template: merge-csv
dependencies: [download-data]
arguments:
artifacts:
- {name: download-data-Data, from: ''}
- name: merge-csv
container:
args: [--file, /tmp/inputs/file/data, --output-csv, /tmp/outputs/output_csv/data]
command:
- sh
- -c
- (PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
'pandas==1.1.4' || PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install
--quiet --no-warn-script-location 'pandas==1.1.4' --user) && "$0" "$@"
- sh
- -ec
- |
program_path=$(mktemp)
printf "%s" "$0" > "$program_path"
python3 -u "$program_path" "$@"
- "def _make_parent_dirs_and_return_path(file_path: str):\n import os\n \
\ os.makedirs(os.path.dirname(file_path), exist_ok=True)\n return file_path\n\
\ndef merge_csv(file_path,\n output_csv):\n import glob\n import\
\ pandas as pd\n import tarfile\n\n tarfile.open(name=file_path, mode=\"\
r|gz\").extractall('data')\n df = pd.concat(\n [pd.read_csv(csv_file,\
\ header=None) \n for csv_file in glob.glob('data/*.csv')])\n df.to_csv(output_csv,\
\ index=False, header=False)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog='Merge\
\ csv', description='')\n_parser.add_argument(\"--file\", dest=\"file_path\"\
, type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"\
--output-csv\", dest=\"output_csv\", type=_make_parent_dirs_and_return_path,\
\ required=True, default=argparse.SUPPRESS)\n_parsed_args = vars(_parser.parse_args())\n\
\n_outputs = merge_csv(**_parsed_args)\n"
image: python:3.8
inputs:
artifacts:
- {name: download-data-Data, path: /tmp/inputs/file/data}
outputs:
artifacts:
- {name: merge-csv-output_csv, path: /tmp/outputs/output_csv/data}
metadata:
labels: {pipelines.kubeflow.org/kfp_sdk_version: 1.6.4, pipelines.kubeflow.org/pipeline-sdk-type: kfp}
annotations: {pipelines.kubeflow.org/component_spec: '{"implementation": {"container":
{"args": ["--file", {"inputPath": "file"}, "--output-csv", {"outputPath":
"output_csv"}], "command": ["sh", "-c", "(PIP_DISABLE_PIP_VERSION_CHECK=1
python3 -m pip install --quiet --no-warn-script-location ''pandas==1.1.4''
|| PIP_DISABLE_PIP_VERSION_CHECK=1 python3 -m pip install --quiet --no-warn-script-location
''pandas==1.1.4'' --user) && \"$0\" \"$@\"", "sh", "-ec", "program_path=$(mktemp)\nprintf
\"%s\" \"$0\" > \"$program_path\"\npython3 -u \"$program_path\" \"$@\"\n",
"def _make_parent_dirs_and_return_path(file_path: str):\n import os\n os.makedirs(os.path.dirname(file_path),
exist_ok=True)\n return file_path\n\ndef merge_csv(file_path,\n output_csv):\n import
glob\n import pandas as pd\n import tarfile\n\n tarfile.open(name=file_path,
mode=\"r|gz\").extractall(''data'')\n df = pd.concat(\n [pd.read_csv(csv_file,
header=None) \n for csv_file in glob.glob(''data/*.csv'')])\n df.to_csv(output_csv,
index=False, header=False)\n\nimport argparse\n_parser = argparse.ArgumentParser(prog=''Merge
csv'', description='''')\n_parser.add_argument(\"--file\", dest=\"file_path\",
type=str, required=True, default=argparse.SUPPRESS)\n_parser.add_argument(\"--output-csv\",
dest=\"output_csv\", type=_make_parent_dirs_and_return_path, required=True,
default=argparse.SUPPRESS)\n_parsed_args = vars(_parser.parse_args())\n\n_outputs
= merge_csv(**_parsed_args)\n"], "image": "python:3.8"}}, "inputs": [{"name":
"file", "type": "Tarball"}], "name": "Merge csv", "outputs": [{"name": "output_csv",
"type": "CSV"}]}', pipelines.kubeflow.org/component_ref: '{}'}
arguments:
parameters:
- {name: url}
serviceAccountName: pipeline-runner
We can easily upload this to kubeflow and we techically have a pipeline.
It is important to mention at this point that this is the foundation of our MLOps pipeline, as we can basically chain various codes and stages together as the above for our running kubeflow environment.
Having set up our environment, our focus now is on Continous integration and deployment of our application and pipeline. I choose a tool called ArgoCD for the continous deployment while using Github Actioins for Continouse integration. I believe seperating this two activities is more or less a best practice for Devops, well enough that the industry coined the word Gitops for that process of Continous deployment adopted by Argocd. Okay so to get the gist of what ArgoCD will do: Continous integration has technically been standardize to end at one of publishing your app as package somewhere or pushing your app as a docker container to the container registry. Once this process concludes, we can then update the app registry on github which is connected to a continous deployment applicaton running somewhere (in our case argocd running on the kubernetes cluster on which our app will run) and this update triggers automatic deployment of our application by getting the latest docker container and running it on the cluster or our specified cluster.
This is not only useful for our MLOps pipeline (basically the model training and deployment part), this is also important for the DataOps stage where we don’t necessarily have to connect it to the Kubeflow pipeline, speaking of this stage, we are speaking of the feature store management which will be deployed predominantly as an application using Feast.
In order not to over-cramp up this portion of the article, I will leave setting up ArgoCD and its usage to Part 4 of this set of articles. In the next 2 articles I will be deploying a feast feature store to kubernetes in a CI/CD verion to mimick how the machine learning engineer helps to cater for differing features of different datasets. This also fundametally lay the foundation for how we will be managing several datasets for several models to be run in production.
Conclusion:
We have come a long way on setting up our orchestration engine. Note that the process is very dependent on how much resource you have locally. I use a 16GB RAM MacOs for this setup. In case you are unable to do local deployment, you can leverage a cloud managed kubernetes cluster for this. It largely follows same deployment approach - not to even say you get a kubernetes cluster managed for you on setup from most of the cloud providers.
If your organization is intending to scale your machine learning pipeline, or having difficulty taking machine learning models into production properly, you can email me at adekunleba@gmail.com for some guidance, i will be more than willing to listen and provide information that most likely will be of help.
Leave a Comment